BCBId: first Bangla comic dataset and its applications
| Tipo | Artículo de revista académica |
|---|---|
| Autor | Arpita Dutta |
| Autor | Samit Biswas |
| Autor | Amit Kumar Das |
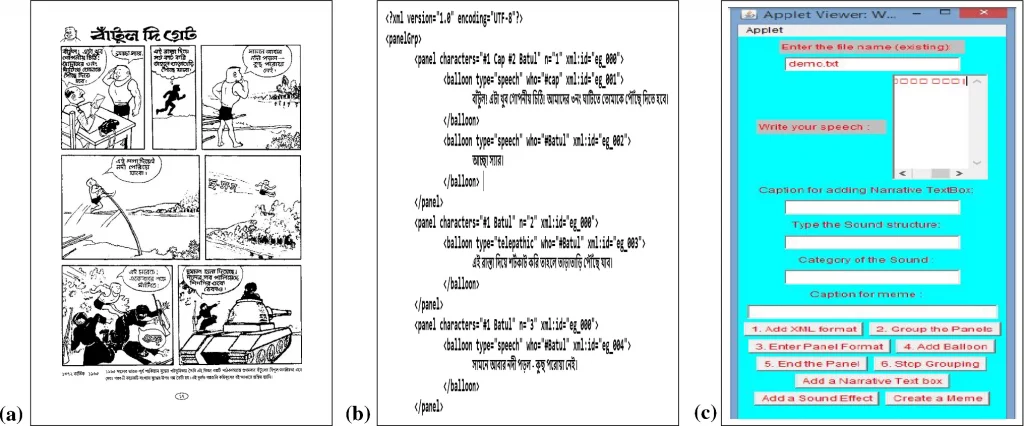
| Resumen | Comic document image analysis is now an active field of research in both academia and industry. However, comic document image processing research suffers due to its inherent complexities and the limited availability of benchmark public datasets. This paper describes the creation of the first-ever comic dataset among Indian Languages, namely Bangla Comic Book Image dataset (BCBId) (https://sites.google.com/view/banglacomicbookdataset), which is also made public for the benefit of the researchers. BCBId consists of 3327 images taken from 64 Bangla comic stories written by 8 writers. Bangla is the 6th most popular spoken language in the world—used by 265 million people (https://en.wikipedia.org/wiki/Languages_of_India), and has a century-old heritage of comic strips (in newspapers) and books. BCBId has the ground truth for extracting various visual components of the comic book images, i.e., panels, characters, speech balloons, and text lines. BCBId also includes the metadata encoding of all images in XML format to describe the underlined structure, semantics, and other features of the documents to pursue research on understanding stories and dialogues. A tool is specifically designed for accurate and faster ground-truth generation. As an application of the dataset, we carry out the sentiment analysis of comic stories—the first-ever attempt on comic book images. We also elaborate on a couple of applications of the BCBId in the comic research domain. Besides, we estimate the errors made by the annotators during the annotation process and describe different evaluation parameters to test the efficacy of the comic document image analysis algorithms.
El análisis de imágenes de cómics es ahora un campo activo de investigación tanto en la academia como en la industria. Sin embargo, la investigación del procesamiento de imágenes de documentos cómicos sufre debido a sus complejidades inherentes y la disponibilidad limitada de conjuntos de datos públicos de referencia. Este documento describe la creación del primer conjunto de datos de historietas entre los idiomas indios, a saber, el conjunto de datos de imágenes de cómics en bengalí (BCBId) (https://sites.google.com/view/banglacomicbookdataset), que también se hace público en beneficio de los investigadores. BCBId consta de 3327 imágenes tomadas de 64 historietas bengalíes escritas por 8 escritores. El bengalí es el sexto idioma hablado más popular en el mundo, utilizado por 265 millones de personas (https://en.wikipedia.org/wiki/Languages_of_India), y tiene una herencia centenaria de tiras cómicas (en periódicos) y libros. BCBId tiene la verdad básica para extraer varios componentes visuales de las imágenes del cómic, es decir, paneles, personajes, globos de diálogo y líneas de texto. BCBId también incluye la codificación de metadatos de todas las imágenes en formato XML para describir la estructura subrayada, la semántica y otras características de los documentos para realizar investigaciones sobre la comprensión de historias y diálogos. Una herramienta está diseñada específicamente para una generación precisa y más rápida de la verdad del terreno. Como una aplicación del conjunto de datos, llevamos a cabo el análisis de sentimientos de las historias de historietas, el primer intento de imágenes de historietas. También elaboramos un par de aplicaciones del BCBId en el dominio de investigación de historietas. Además, estimamos los errores cometidos por los anotadores durante el proceso de anotación y describimos diferentes parámetros de evaluación para probar la eficacia de los algoritmos de análisis de imágenes de documentos cómicos. |
| URL | https://doi.org/10.1007/s10032-022-00412-9 |
| Accedido | 22/9/2022 9:47:14 |
| Publicación | International Journal on Document Analysis and Recognition (IJDAR) |
| DOI | 10.1007/s10032-022-00412-9 |
| Abrev. de revista | IJDAR |
| ISSN | 1433-2825 |
Leave a Reply